| Chapter 7 Input/Output and Command-line Processing |  |

| Chapter 7 Input/Output and Command-line Processing | |
We've seen how the shell uses
read to process input lines: it deals with single
quotes (' '), double quotes (" "), and backslashes
(\); it separates lines into
words, according to delimiters in the environment variable IFS;
and it assigns the words to shell variables. We can think of this
process as a subset of the things the shell does when processing
command lines.
We've touched upon command-line processing (see Figure 7.1) throughout this book; now is a good time to make the whole thing explicit. [7] Each line that the shell reads from the standard input or a script is called a pipeline; it contains one or more commands separated by zero or more pipe characters (|). For each pipeline it reads, the shell breaks it up into commands, sets up the I/O for the pipeline, then does the following for each command:
[7] Even this explanation is slightly simplified to elide the most petty details, e.g., "middles" and "ends" of compound commands, special characters within [[...]] and ((...)) constructs, etc. The last word on this subject is the reference book, The KornShell Command and Programming Language, by Morris Bolsky and David Korn, published by Prentice-Hall.
Splits the command into tokens that are separated by
the fixed set of metacharacters: SPACE, TAB, NEWLINE, ;,
(, ),
<, >, |, and &. Types of tokens include words, keywords,
I/O redirectors, and semicolons.
Checks the first token of each command to see if it is a keyword with no quotes or backslashes. If it's an opening keyword (if and other control-structure openers, function, {, (, ((, or [[), then the command is actually a compound command. The shell sets things up internally for the compound command, reads the next command, and starts the process again. If the keyword isn't a compound command opener (e.g., is a control-structure "middle" like then, else, or do, an "end" like fi or done, or a logical operator), the shell signals a syntax error.
Checks the first word of each command against the list of aliases. If a match is found, it substitutes the alias' definition and goes back to Step 1; otherwise it goes on to Step 4. This scheme allows recursive aliases; see Chapter 3. It also allows aliases for keywords to be defined, e.g., alias aslongas=while or alias procedure=function.
Substitutes the user's home directory ($HOME) for tilde if
it is at the beginning of a word. Substitutes user's home
directory for ~user.
[8]
[8] Two obscure variations on this: the shell substitutes the current directory ($PWD) for ~+ and the previous directory ($OLDPWD) for ~-.
Performs parameter (variable) substitution for any expression that starts with a dollar sign ($).
Does command substitution for any expression of the form $(string).
Takes the parts of the line that resulted from parameter, command, and arithmetic substitution and splits them into words again. This time it uses the characters in $IFS as delimiters instead of the set of metacharacters in Step 1.
Performs filename generation, a.k.a.
wildcard expansion,
for any occurrences of *, ?,
and [/] pairs.
It also processes the regular
expression operators that we saw in Chapter 4.
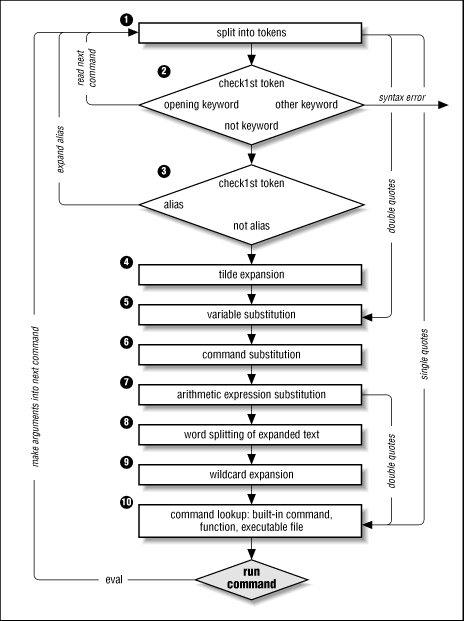
Uses the first word as a command by looking up its source according to the rest of the list in Chapter 4, i.e., as a built-in command, then as a function, then as a file in any of the directories in $PATH.
Runs the command after setting up I/O redirection and other such things.
That's a lot of steps - and it's not even the whole story! But before we go on, an example should make this process clearer. Assume that the following command has been run:
alias ll="ls -l"
Further assume that a file exists called .hist537 in user fred's home directory, which is /home/fred, and that there is a double-dollar-sign variable $$ whose value is 2537 (we'll see what this special variable is in the next chapter).
Now let's see how the shell processes the following command:
ll $(whence cc) ~fred/.*$(($$%1000))
Here is what happens to this line:
ll $(whence cc) ~fred/.*$(($$%1000))
Splitting the input into words.
ll is not a keyword, so step 2 does nothing.
ls -l $(whence cc) ~fred/.*$(($$%1000))
Substituting ls -l for its alias "ll". The shell then repeats steps 1 through 3; step 2 splits the ls -l into two words. [9]
[9] Some of the shell's built-in aliases, however, seem to make it through single quotes: true (an alias for :, a "do-nothing" command that always returns exit status 0), false (an alias for let 0, which always returns exit status 1), and stop (an alias for kill -STOP).
ls -l $(whence cc) /home/fred/.*$(($$%1000))
Expanding ~fred into /home/fred.
ls -l $(whence cc) /home/fred/.*$((2537%1000))
Substituting 2537 for $$.
ls -l /usr/bin/cc /home/fred/.*$((2537%1000))
Doing command substitution on "whence cc".
ls -l /usr/bin/cc /home/fred/.*537
Evaluating the arithmetic expression 2537%1000.
ls -l /usr/bin/cc /home/fred/.*537
This step does nothing.
ls -l /usr/bin/cc /home/fred/.hist537
Substituting the filename for the wildcard expression .*537.
The command ls is found in /usr/bin.
/usr/bin/ls is run with the option -l and the two arguments.
Although this list of steps is fairly straightforward, it is not the whole story. There are still two ways to subvert the process: by quoting and by using the advanced command eval.
You can think of quoting as a way of getting the shell to skip some of the 11 steps above. In particular:
Single quotes ( ' ') bypass everything through
Step 9 - including aliasing.
[10]
All characters inside a pair of single quotes are untouched.
You can't have single quotes inside single quotes - not even
if you precede them with backslashes.
[10] However, as we saw in Chapter 1
'\''(i.e., single quote, backslash, single quote, single quote) acts pretty much like a single quote in the middle of a single-quoted string; e.g.,'abc'\''def'evaluates to abc'def.
Double quotes (" ") bypass steps 1 through 4, plus steps 8 and 9. That is, they
ignore pipe characters, aliases, tilde substitution, wildcard expansion,
and splitting into words via delimiters (e.g., blanks)
inside the double quotes. Single quotes inside double quotes have
no effect. But double quotes do allow parameter substitution,
command substitution, and arithmetic
expression evaluation. You can include a double quote inside a
double-quoted string by preceding it with a backslash
(\). You must
also backslash-escape $, ` (the archaic
command substitution delimiter), and \ itself.
Table 7.5 contains some simple examples that show how these work; they assume that the statement dave=bob was run and that user fred's home directory is /home/fred.
If you are wondering whether to use single or double quotes in a particular shell programming situation, it is safest to use single quotes unless you specifically need parameter, command, or arithmetic substitution.
| Expression | Value |
|---|---|
| $dave | bob |
| "$dave" | bob |
| \\$dave | $dave |
'$dave' | $dave |
'$dave' | 'bob' |
| ~fred | /home/fred |
"~fred" | ~fred |
'~fred' | ~fred |
Here's a more advanced example of command-line processing that should give you deeper insight into the overall process.
Customize your primary prompt string so that it contains the current directory with tilde (~) notation.
Recall from Chapter 4 that we found a simple way to set up the prompt string PS1 so that it always contains the current directory:
PS1='($PWD)-> '
One problem with this setup is that the resulting prompt strings can get very long. One way to shorten them is to substitute tilde notation for users' home directories. This cannot be done with a simple string expression analogous to the above. The solution is somewhat complicated and takes advantage of the command-line processing rules.
The basic idea is to create a "wrapper" around the cd command, as we did in Chapter 5, that installs the current directory with tilde notation as the prompt string. Because cd is a built-in command, the wrapper must be an alias in order to override it. But the code we need to insert tilde notation is too complicated for an alias, so we'll use a function and then alias the function as cd.
We'll start with a function that, given a pathname as argument, prints its equivalent in tilde notation if possible:
function tildize {
if [[ $1 = $HOME* ]]; then
print "\~/${1#$HOME}"
return 0
fi
awk '{FS=":"; print $1, $6}' /etc/passwd |
while read user homedir; do
if [[ $homedir != / && $1 = ${homedir}?(/*) ]]; then
print "\~$user/${1#$homedir}"
return 0
fi
done
print "$1"
return 1
}The first if clause checks if the given pathname is under the user's home directory. If so, it substitutes tilde (~) for the home directory in the pathname and returns.
If not, we use the awk utility to extract the
first and sixth fields of the file /etc/passwd, which contain
users IDs and home directories, respectively. In this case,
awk acts like cut.
The FS=":" is analogous to
-d:, which we saw in Chapter 4, except that it prints the
values on each line separated by blanks, not colons (:).
awk's output is fed into a while loop that checks the pathname given as argument to see if it contains some user's home directory. (The first part of the conditional expression eliminates "users" like daemon and root, whose home directories are root and therefore are contained in every full pathname.The second part matches home directories by themselves or with some other directory appended (the ?(/*) part.)) If a user's home directory is found, then ~user is substituted for the full home directory in the given pathname, the result is printed, and the function exits.
Finally, if the while loop exhausts all users without finding a home directory that is a prefix of the given pathname, then tildize simply echoes back its input.
Now that we have this function, you might think we could use it in a command substitution expression like this:
PS1='$(tildize $PWD)'
But this won't work, because the shell doesn't do command substitution when it evaluates the prompt string after every command. That's why we have to incorporate it into an alias that supersedes cd. The following code should go into your .profile or environment file, along with the definition of tildize:
PS1=$(tildize $PWD)
function _cd {
"cd" "$@"
es=$?
PS1=$(tildize $PWD)
return $es
}
alias cd=_cdWhen you log in, this code will set PS1 to the initial current directory (presumably your home directory). Then, whenever you enter a cd command, the alias runs the function _cd, which looks a lot like the "wrapper" in Chapter 5.
The first line in _cd runs the "real" cd by surrounding it in quotes - which makes the shell bypass alias expansion (Step 3 in the list). Then the shell resets the prompt string to the new current directory, or the old one if the cd failed for some reason.
Of course, the function tildize can be any code that formats the directory string. See the exercises at the end of this chapter for a couple of suggestions.
We have seen that quoting lets you skip steps in command-line processing. Then there's the eval command, which lets you go through the process again. Performing command-line processing twice may seem strange, but it's actually very powerful: it lets you write scripts that create command strings on the fly and then pass them to the shell for execution. This means that you can give scripts "intelligence" to modify their own behavior as they are running.
The eval statement tells the shell to take eval's arguments and run them through the command-line processing steps all over again. To help you understand the implications of eval, we'll start with a trivial example and work our way up to a situation in which we're constructing and running commands on the fly.
eval ls passes the string ls to the shell to execute; the shell prints list of files in the current directory. Very simple; there is nothing about the string ls that needs to be sent through the command-processing steps twice. But consider this:
listpage="ls | more" $listpage
Instead of producing a paginated file listing, the shell will treat | and more as arguments to ls, and ls will complain that no files of those names exist. Why? Because the pipe character "appears" in step 5 when the shell evaluates the variable, after it has actually looked for pipe characters (in step 2). The variable's expansion isn't even parsed until step 8. As a result, the shell will treat | and more as arguments to ls, so that ls will try to find files called | and more in the current directory!
Now consider eval $listpage instead of just $listpage. When the shell gets to the last step, it will run the command eval with arguments ls, |, and more. This causes the shell to go back to Step 1 with a line that consists of these arguments. It finds | in Step 2 and splits the line into two commands, ls and more. Each command is processed in the normal (and in both cases trivial) way. The result is a paginated list of the files in your current directory.
Now you may start to see how powerful eval can be. It is an advanced feature that requires considerable programming cleverness to be used most effectively. It even has a bit of the flavor of artificial intelligence, in that it enables you to write programs that can "write" and execute other programs. [11] You probably won't use eval for everyday shell programming, but it's worth taking the time to understand what it can do.
[11] You could actually do this without eval, by printing commands to a temporary file and then "sourcing" that file with . filename. But that is much less efficient.
As a more interesting example, we'll revisit Task 4-1, the very first task in the book. In it, we constructed a simple pipeline that sorts a file and prints out the first N lines, where N defaults to 10. The resulting pipeline was:
sort -nr $1 | head -${2:-10}The first argument specified the file to sort; $2 is the number of lines to print.
Now suppose we change the task just a bit so that the default is to print the entire file instead of 10 lines. This means that we don't want to use head at all in the default case. We could do this in the following way:
if [[ -n $2 ]]; then
sort -nr $1 | head -$2
else
sort -nr $1
fiIn other words, we decide which pipeline to run according to whether or not $2 is null. But here is a more compact solution:
eval sort -nr \$1 ${2:+"| head -\$2"}The last expression in this line evaluates to the string | head -\$2 if $2 exists (is not null); if $2 is null, then the expression is null too. We backslash-escape dollar signs (\$) before variable names to prevent unpredictable results if the variables' values contain special characters like > or |. The backslash effectively puts off the variables' evaluation until the eval command itself runs. So the entire line is either:
eval sort -nr \$1 | head -\$2
if $2 is given or:
eval sort -nr \$1
if $2 is null. Once again, we can't just run this command without eval because the pipe is "uncovered" after the shell tries to break the line up into commands. eval causes the shell to run the correct pipeline when $2 is given.
Next, we'll revisit Task 7-3 from earlier in this chapter, the start script that lets you start a command in the background and save its standard output and standard error in a logfile. Recall that the one-line solution to this task had the restriction that the command could not contain output redirectors or pipes. Although the former doesn't make sense when you think about it, you certainly would want the ability to start a pipeline in this way.
eval is the obvious way to solve this problem:
eval "$@" > logfile 2>&1 &
The only restriction that this imposes on the user is that pipes and other such special characters be quoted (surrounded by quotes or preceded by backslashes).
Here's a way to apply eval in conjunction with various other interesting shell programming concepts.
Implement the guts of the make(1) utility as a shell script.
make is known primarily as a programmer's tool, but it seems as though someone finds a new use for it every day. Without going into too much extraneous detail, make basically keeps track of multiple files in a particular project, some of which depend on others (e.g., a document depends on its word processor input file(s)). It makes sure that when you change a file, all of the other files that depend on it are processed.
For example, assume you're using the troff word processor to write a book. You have files for the book's chapters called ch1.t, ch2.t, and so on; the troff output for these files are ch1.out, ch2.out, etc. You run commands like troff chN.t > chN.out to do the processing. While you're working on the book, you tend to make changes to several files at a time.
In this situation, you can use make to keep track of which files need to be reprocessed, so that all you need to do is type make, and it will figure out what needs to be done. You don't need to remember to reprocess the files that have changed.
How does make do this? Simple: it compares the modification times of the input and output files (called sources and targets in make terminology), and if the input file is newer, then make reprocesses it.
You tell make which files to check by building a file called makefile that has constructs like this:
target:source1 source2 ... commands to make target
This essentially says, "For target to be up to date, it must be newer than all of the sources. If it's not, run the commands to bring it up to date." The commands are on one or more lines that must start with TABs: e.g., to make ch7.out:
ch7.out : ch7.t troff ch7.t > ch7.out
Now suppose that we write a shell function called makecmd that reads and executes a single construct of this form. Assume that the makefile is read from standard input. The function would look like the following code.
function makecmd {
read target colon sources
for src in $sources; do
if [[ $src -nt $target ]]; then
while read cmd && [[ $cmd = \t* ]]; do
print "$cmd"
eval ${cmd#\t}
done
break
fi
done
}This function reads the line with the target and sources; the variable colon is just a placeholder for the :. Then it checks each source to see if it's newer than the target, using the -nt file attribute test operator that we saw in Chapter 5. If the source is newer, it reads, prints, and executes the commands until it finds a line that doesn't start with a TAB or it reaches end-of-file. (The real make does more than this; see the exercises at the end of this chapter.) After running the commands (which are stripped of the initial TAB), it breaks out of the for loop, so that it doesn't run the commands more than once.
As a final example of eval, we'll revisit our old friend occ, the C compiler from the previous three chapters. Recall that the compiler does its work by calling separate programs to do the actual compile from C to object code (the ccom program), optimization of object code (optimize), assembly of assembler code files (as), and final linking of object code files into an executable program (ld). These separate programs use temporary files to store their outputs.
Now we'll assume that these components (except the linker) pass information in a pipeline to the final object code output. In other words, each component takes standard input and produces standard output instead of taking filename arguments. We'll also change an earlier assumption: instead of compiling a C source file directly to object code, occ compiles C to assembler code, which the assembler then assembles to object code. This lets us suppose that occ works like this:
ccom < filename.c | as | optimize > filename.o
Or, if you prefer:
cat filename.c | ccom | as | optimize >filename.o
To get this in the proper framework for eval, let's assume that the variables srcname and objname contain the names of the source and object files, respectively. Then our pipeline becomes:
cat $srcname | ccom | as | optimize > $objname
As we've already seen, this is equivalent to:
eval cat \$srcname | ccom | as | optimize > \$objname
Knowing what we do about eval, we can transform this into:
eval cat \$srcname " | ccom" " | as" " | optimize" > \$objname
and from that into:
compile=" | ccom" assemble=" | as" optimize=" | optimize" eval cat \$srcname \$compile \$assemble \$optimize > \$objname
Now, consider what happens if you don't want to invoke the optimizer - which is the default case anyway. (Recall that the -O option invokes the optimizer.) We can do this:
optimize=""
if -O given then
optimize=" | optimize"
fiIn the default case, $optimize evaluates to the empty string, causing the final pipeline to "collapse" into:
eval cat $srcname | ccom | as > $objname
Similarly, if you pass occ a file of assembler code (filename.s), you can collapse the compile step: [12]
[12] Astute readers will notice that, according to this rationale, we would handle object-code input files (filename.o) with the pipeline eval cat $srcname > $objname, where the two names are the same. This will cause UNIX to destroy filename.o by truncating it to zero length. We won't worry about this here.
assemble="| as"
if $srcname ends in .s then
compile=""
fiThat results in this pipeline:
eval cat \$srcname | as > \$objname
Now we're ready to show the full "pipeline" version of occ. It's similar to the previous version, except that for each input file, it constructs and runs a pipeline as above. It processes the -g (debug) option and the link step in the same way as before. Here is the code:
# initialize option-related variables
do_link=true
debug=""
link_libs="-l c"
exefile=""
# initialize pipeline components
compile=" | ccom"
assemble=" | as"
optimize=""
# process command-line options
while getopts ":cgl:o:O" opt; do
case $opt in
c ) do_link=false ;;
g ) debug="-g" ;;
l ) link_libs="$link_libs -l $OPTARG" ;;
o ) exefile="-o $OPTARG" ;;
O ) optimize=" | optimize" ;;
\? ) print 'usage: occ [-cgO] [-l lib] [-o file] files...'
return 1 ;;
esac
done
shift $(($OPTIND - 1))
# process the input files
for filename in "$@"; do
case $filename in
*.c )
objname=${filename%.c}.o ;;
*.s )
objname=${filename%.s}.o
compile="" ;;
*.o )
compile=""
assemble="" ;;
* )
print "error: $filename is not a source or object file."
return 1 ;;
esac
# run a pipeline for each input file
eval cat \$filename \$compile \$assemble \$optimize > \$objname
objfiles=$objfiles" "$objname
done
if [[ $do_link = true ]]; then
ld $exefile $link_libs $objfiles
fiWe could go on forever with increasingly complex examples of eval, but we'll settle for concluding the chapter with a few exercises. The last two are really more like items on the menu of food for thought; the very last one is particularly difficult.
Here are a couple of ways to enhance occ, our C compiler:
Real-world C compilers accept the option -S, which tells the compiler to suppress the assembly step and leave the output in files of assembler code whose names end in .s. Modify occ so that it recognizes this option.
The language C++ is an evolutionary successor to C; it includes advanced features like operator overloading, function argument type checking, and class definitions. (Don't worry if you don't know what these are.) Some C++ compilers use C as an "assembly language", i.e., they compile C++ source files to C code and then pass them to a C compiler for further processing. Assume that C++ source files have names ending in .cc, and that /lib/cfront is the C++ compiler "front-end" that produces C code on its standard output. Modify occ so that it accepts C++ as well as C, assembler, and object code files.
The possibilities for customizing your prompt string are practically endless. Here are two enhancements to customization schemes that we've seen already:
Enhance the current-directory-in-the-prompt scheme by limiting the prompt string's length to a number of characters that the user can define with an environment variable.
On some UNIX systems, it's not possible to get a list of all users by looking at /etc/passwd. For example, networks of Suns use the Network Information Service (NIS, a.k.a. "Yellow Pages"), which stores a protected password file for the entire network on one server machine, instead of having separate /etc/passwd files on each machine.
If such a machine is set up so that all login directories are under a common directory (e.g., /users), you can get a list of all users by simply ls-ing that directory. Modify the tildize function so that it uses this technique; pay particular attention to execution speed.
The function makecmd in the solution to Task 7-6 represents an oversimplification of the real make's functionality. make actually checks file dependencies recursively, meaning that a source on one line in a makefile can be a target on another line. For example, the book chapters in the example could themselves depend on some figures in separate files that were made with a graphics package.
Write a function called readtargets that goes through the makefile and stores all of the targets in a variable or temp file.
Instead of reading the makefile from standard input, read it into an array variable called lines. Use the variable curline as the "current line" index. Modify makecmd so that it reads lines from the array starting with the current line.
makecmd merely checks to see if any of the sources are newer than the given target. It should really be a recursive routine that looks like this:
function makecmd {
target=$1
get sources for $target
for each source src; do
if $src is also a target in this makefile then
makecmd $src
fi
if [[ $src -nt $target ]]; then
run commands to make target
return
fi
done
}Implement this.
Write the "driver" script that turns the makecmd function into a full make program. This should make the target given as argument, or if none is given, the first target listed in the makefile.
The above makecmd still doesn't do one important thing that the real make does: allow for "symbolic" targets that aren't files. These give make much of the power that makes it applicable to such an incredible variety of situations. Symbolic targets always have a modification time of 0, so that make always runs the commands to make them. Modify makecmd so that it allows for symbolic targets. (Hint: the crux of this problem is to figure out how to get a file's modification time. This is quite difficult.)
Finally, here are some problems that really test your knowledge of eval and the shell's command-line processing rules. Solve these and you're a true Korn shell hacker!
Advanced shell programmers sometimes use a little trick that includes eval: using the value of a variable as the name of another variable. In other words, you can give a shell script control over the names of variables to which it assigns values. How would you do this? (Hint: if $fred equals "dave", and $dave is "bob", then you might think that you could type print $$fred and get the response bob. This doesn't actually work, but it's on the right track.)
You could use the above technique together with other eval tricks to implement new control structures for the shell. For example, see if you can write a script that emulates the behavior of a for loop in a conventional language like C or Pascal, i.e., a loop that iterates a fixed number of times, with a loop variable that steps from 1 to the number of iterations (or, for C fans, 0 to iterations-1). Call your script loop to avoid clashes with the keywords for and do.
|  | |
| 7.2 String I/O |  | 8. Process Handling |